很久沒看過360的站長平臺了,于是在360搜索中site了一把,發現居然安全評分是99,而不是100。好奇點進去看了下,發現下面這個大奇葩:
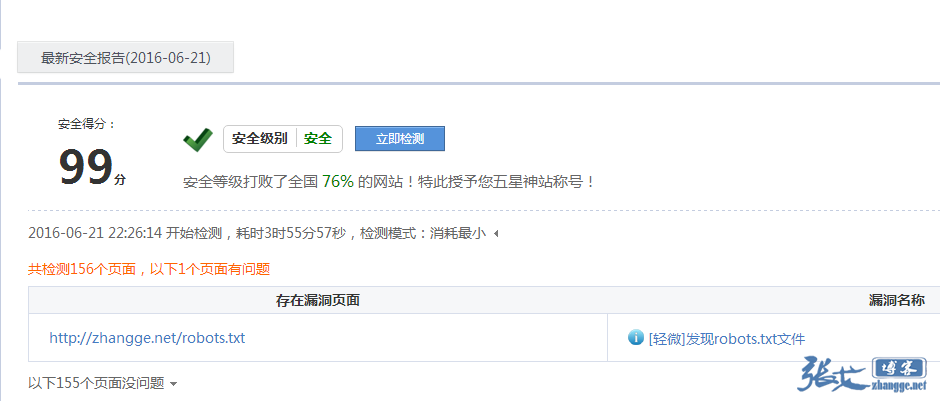
吶尼?發現robots.txt文件?這也算漏洞?繼續看了下解釋:
大概是懂了,就是robots會泄漏網站后臺或其他敏感地址,我之前遇到不想讓人通過robots知道的地址,我也會使用上述解決辦法中的第3條,只寫局部字符串。
- 漏洞類型:
- 信息泄露
- 所屬建站程序:
- 其他
- 所屬服務器類型:
- 通用
- 所屬編程語言:
- 其他
- 描述:
- 目標WEB站點上發現了robots.txt文件。
1.robots.txt是搜索引擎訪問網站的時候要查看的第一個文件。
- 收起
2.robots.txt文件會告訴蜘蛛程序在服務器上什么文件是可以被查看的什么文件是不允許查看的。舉一個簡單的例子:當一個搜索蜘蛛訪問一個站點時,它會首先檢查該站點根目錄下是否存robots.txt,如果存在,搜索機器人就會按照該文件中的內容來確定訪問的范圍;如果該文件不存在,所有的搜索蜘蛛將能夠訪問網站上所有沒有被口令保護的頁面。同時robots.txt是任何人都可公開訪問的,惡意攻擊者可以通過分析robots.txt的內容,來獲取敏感的目錄或文件路徑等信息。
- 危害:
- robots.txt文件有可能泄露系統中的敏感信息,如后臺地址或者不愿意對外公開的地址等,惡意攻擊者有可能利用這些信息實施進一步的攻擊。
- 解決方案:
- 1. 確保robots.txt中不包含敏感信息,建議將不希望對外公布的目錄或文件請使用權限控制,使得匿名用戶無法訪問這些信息
2. 將敏感的文件和目錄移到另一個隔離的子目錄,以便將這個目錄排除在Web Robot搜索之外。如將文件移到“folder”之類的非特定目錄名稱是比較好的解決方案: New directory structure: /folder/passwords.txt/folder/sensitive_folder/
New robots.txt: User-agent: * Disallow: /folder/
3. 如果您無法更改目錄結構,且必須將特定目錄排除于 Web Robot 之外,在 robots.txt 文件中,請只用局部名稱。雖然這不是最好的解決方案,但至少它能加大完整目錄名稱的猜測難度。例如,如果要排除“admin”和“manager”,請使用下列名稱(假設 Web 根目錄中沒有起始于相同字符的文件或目錄): robots.txt:
User-agent: *
Disallow: /ad
Disallow: /ma
原文地址:http://webscan.360.cn/vul/view/vulid/139
但是,這些完全是掩耳盜鈴的做法,明眼人都能輕松識別博客是WordPress還是其他建站程序,什么敏感目錄根本沒法隱藏,當然隱藏了也沒啥用。
不過,看到不是100分就不爽,所以我也掩耳盜鈴的解決一下吧!
我的思路很簡單,對于非蜘蛛抓取 robots.txt 行為一律返回403,也就是robots.txt 只對蜘蛛開放。實現非常簡單,在 Nginx 配置中加入如下代碼即可:
#如果請求的是robots.txt,并且匹配到了蜘蛛,則返回403
location = /robots.txt {
if ($http_user_agent !~* "spider|bot|Python-urllib|pycurl") {
return 403;
}
}
加入后reload以下Nginx,然后再到瀏覽器訪問robots地址,應該能看到禁止訪問403了。
隨即去360掃描了一把,結果并不意外:
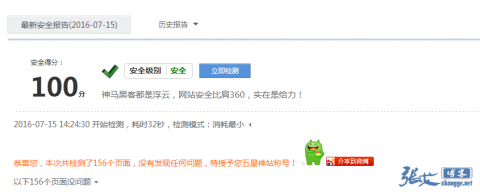
轉載請注明出處 AE博客|墨淵 ? 簡單修復360安全檢測提示的發現robots文件漏洞
發表評論