我們的目標是用爬蟲來干一件略污事情
最近聽說煎蛋上有好多可愛的妹子,而且爬蟲從妹子圖抓起練手最好,畢竟動力大嘛。而且現在網絡上的妹子很黃很暴力,一下接受太多容易營養不量,但是本著有人身體就比較好的套路,特意分享下用點簡單的技術去獲取資源。
以后如果有機會,再給大家說說日本愛情動(大)作(霧)片的種子搜索爬取,多多關注。

請先準備
作案工具
我們只準備最簡單的
需要用到的包
也可以用下面的命令快速安裝
干正事
從一次正常需求說起
每天在互聯網上沖來沖去,瀏覽著大量的信息,觀看這各種鼻血噴發的圖片,于是作為新時代青年的我們,怎么能忍受被這些大量的垃圾信息充斥的互聯網,我們要反抗,我們要下載!
請,看,下,圖
↓

當你在網上沖浪的時候遇到這樣的圖片,我就問你:
虐不虐?虐死了!
下不下?下!
開始吧
獲取圖片的CSS選擇器的規則
首先,我們需要定位我們需要的圖片
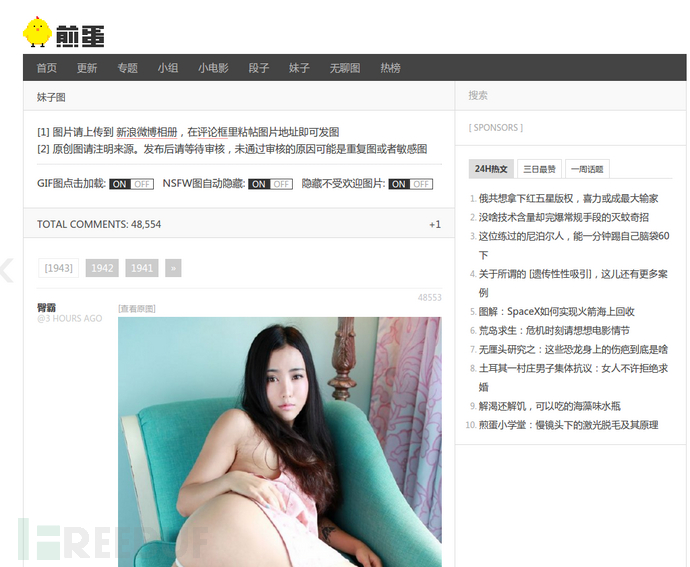
根據我們之前的準備的作案工具,使用chrome來訪問網頁http://jandan.net/ooxx
然后打開開發者工具菜單 -> 更多工具 -> 開發者工具
看下圖右邊的神器
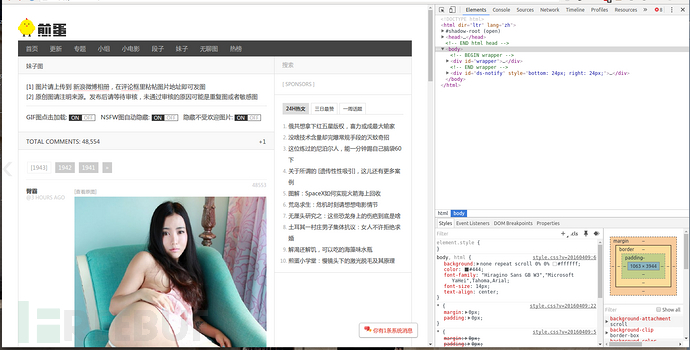
點擊這個圖標會出現塊選擇器,
鼠標移動我們感興趣的部分
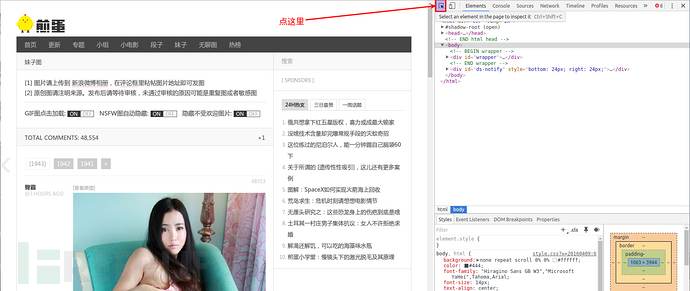
按照圖片指示點擊區域
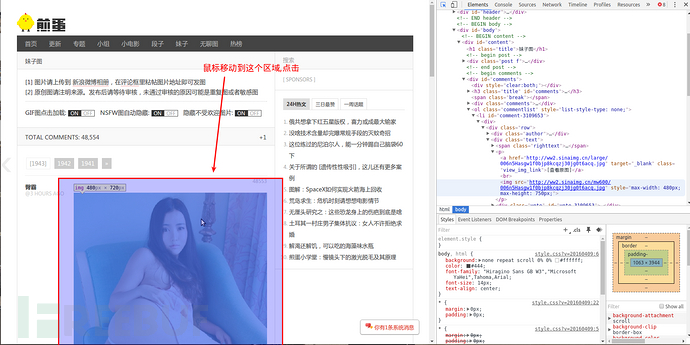
右邊神器中就會出現我們所需要的img標簽
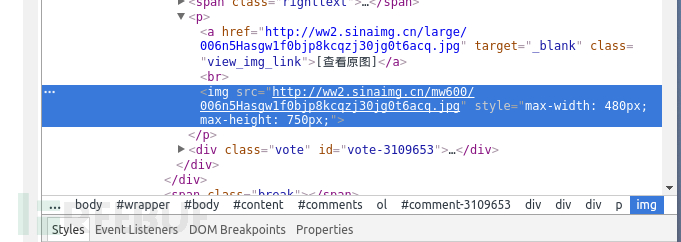
查看之前最后一個以#comments開頭的標簽,
它包含了所有img的子標簽。
下面讓我們來一些
神秘的事
打開cmd或者終端
輸入python
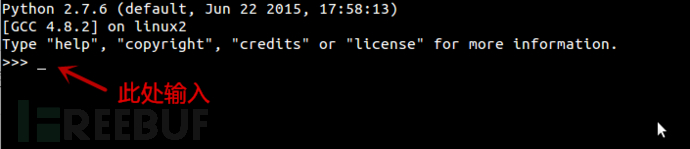
輸入以下神秘代碼
import requests
from bs4 import BeautifulSoup
res = requests.get('http://jandan.net/ooxx')
html = BeautifulSoup(res.text) for index, each in enumerate(html.select('#comments img')):
with open('{}.jpg'.format(index), 'wb') as jpg:
jpg.write(requests.get(each.attrs['src'], stream=True).content) 現在偷偷看一下你的當前目錄
是不是有很多(污)的圖片
咳咳是這樣的
↓
名詞解釋
網絡爬蟲
網絡爬蟲(又被稱為網頁蜘蛛,網絡機器人,在FOAF社區中間,更經常的稱為網頁追逐者),是一種按照一定的規則,自動地抓取萬維網信息的程序或者腳本。另外一些不常使用的名字還有螞蟻、自動索引、模擬程序或者蠕蟲。
爬蟲的使用對很多工作都是很有用的,但是對一般的社區,也需要付出代價。使用爬蟲的代價包括:
適用場景
是不是還不夠
行蹤不定的下期預告
轉載請注明出處 AE博客|墨淵 ? 手把手教你用Python爬蟲煎蛋妹紙海量圖片
發表評論