
計算機通信原理
互聯網的關鍵技術就是TCP/IP協議。兩臺計算機之間的通信是通過TCP/IP協議在因特網上進行的。實際上這個是兩個協議:
- TCP: Transmission Control Protocol 傳輸控制協議
- IP: Internet Protocol 網際協議。
引自維基百科TCP/IP協議族是一個網絡通信模型,以及一整個網絡傳輸協議家族,為互聯網的基礎通信架構。該協議家族的兩個核心協議:TCP(傳輸控制協議)和IP(網際協議),為該家族中最早通過的標準。這個協議族由互聯網工程任務組負責維護。
TCP: 應用程序之間的通信
TCP確保數據包以正確的次序到達,并且嘗試確認數據包的內容沒有改變。TCP在IP地址之上引端口(port),它允許計算機通過網絡提供各種服務。一些端口號為不同的服務保留,而且這些端口號是眾所周知。
服務或者守護進程:在提供服務的機器上,有程序監聽特定端口上的通信流。例如大多數電子郵件通信流出現在端口25上,用于wwww的HTTP通信流出現在80端口上。
當應用程序希望通過 TCP 與另一個應用程序通信時,它會發送一個通信請求。這個請求必須被送到一個確切的地址。在雙方“握手”之后,TCP 將在兩個應用程序之間建立一個全雙工 (full-duplex) 的通信,占用兩個計算機之間整個的通信線路。TCP 用于從應用程序到網絡的數據傳輸控制。TCP 負責在數據傳送之前將它們分割為 IP 包,然后在它們到達的時候將它們重組。
TCP/IP 就是TCP 和 IP 兩個協議在一起協同工作,有上下層次的關系。
TCP 負責應用軟件(比如你的瀏覽器)和網絡軟件之間的通信。IP 負責計算機之間的通信。TCP 負責將數據分割并裝入 IP 包,IP 負責將包發送至接受者,傳輸過程要經IP路由器負責根據通信量、網絡中的錯誤或者其他參數來進行正確地尋址,然后在它們到達的時候重新組合它們。
IP: 計算機之間的通信
IP協議是計算機用來相互識別的通信的一種機制,每臺計算機都有一個IP.用來在internet上標識這臺計算機。 IP 負責在因特網上發送和接收數據包。通過 IP,消息(或者其他數據)被分割為小的獨立的包,并通過因特網在計算機之間傳送。IP 負責將每個包路由至它的目的地。
IP協議僅僅是允許計算機相互發消息,但它并不檢查消息是否以發送的次序到達而且沒有損壞(只檢查關鍵的頭數據)。為了提供消息檢驗功能,直接在IP協議上設計了傳輸控制協議TCP。
HTTP
HTTP概念
引自維基百科HTTP:超文本傳輸協議(英文:HyperText Transfer Protocol,縮寫:HTTP)是一種用于分布式、協作式和超媒體信息系統的應用層協議。HTTP是萬維網的數據通信的基礎。 設計HTTP最初的目的是為了提供一種發布和接收HTML頁面的方法。通過HTTP或者HTTPS協議請求的資源由統一資源標識符(Uniform Resource Identifiers,URI)來標識。
HTTP協議層
HTTP(HyperText Transfer Protocol),超文本傳輸協議,是一個基于TCP實現的應用層協議。
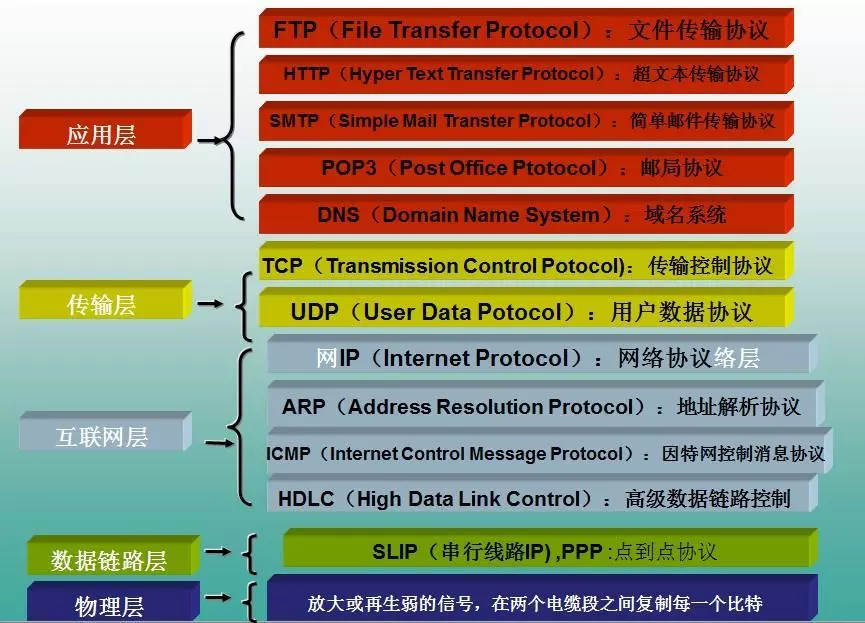
HTTP請求響應模型
HTTP由請求和響應構成,是一個標準的客戶端服務器模型(B/S)。HTTP協議永遠都是客戶端發起請求,服務器回送響應。見下圖:
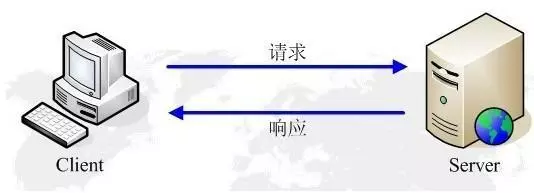
HTTP是一個無狀態的協議。無狀態是指客戶機(Web瀏覽器)和服務器之間不需要建立持久的連接,這意味著當一個客戶端向服務器端發出請求,然后服務器返回響應(response),連接就被關閉了,在服務器端不保留連接的有關信息.HTTP遵循請求(Request)/應答(Response)模型。客戶機(瀏覽器)向服務器發送請求,服務器處理請求并返回適當的應答。所有HTTP連接都被構造成一套請求和應答。
HTTP工作過程
一次HTTP操作稱為一個事務,其工作整個過程如下:
地址解析
如用客戶端瀏覽器請求這個頁面:http://localhost.com:8080/index.htm
從中分解出協議名、主機名、端口、對象路徑等部分,對于我們的這個地址,解析得到的結果如下:
協議名:http
主機名:localhost.com
端口:8080
對象路徑:/index.htm 在這一步,需要域名系統DNS解析域名localhost.com,得主機的IP地址。
封裝HTTP請求數據包
把以上部分結合本機自己的信息,封裝成一個HTTP請求數據包
封裝成TCP包,建立TCP連接(TCP的三次握手)
在HTTP工作開始之前,客戶機(Web瀏覽器)首先要通過網絡與服務器建立連接,該連接是通過TCP來完成的,該協議與IP協議共同構建Internet,即著名的TCP/IP協議族,因此Internet又被稱作是TCP/IP網絡。HTTP是比TCP更高層次的應用層協議,根據規則,只有低層協議建立之后才能,才能進行更層協議的連接,因此,首先要建立TCP連接,一般TCP連接的端口號是80。這里是8080端口。
客戶機發送請求命令
建立連接后,客戶機發送一個請求給服務器,請求方式的格式為:統一資源標識符(URL)、協議版本號,后邊是MIME信息包括請求修飾符、客戶機信息和可內容。
服務器響應
服務器接到請求后,給予相應的響應信息,其格式為一個狀態行,包括信息的協議版本號、一個成功或錯誤的代碼,后邊是MIME信息包括服務器信息、實體信息和可能的內容。
實體消息是服務器向瀏覽器發送頭信息后,它會發送一個空白行來表示頭信息的發送到此為結束,接著,它就以Content-Type應答頭信息所描述的格式發送用戶所請求的實際數據
服務器關閉TCP連接
一般情況下,一旦Web服務器向瀏覽器發送了請求數據,它就要關閉TCP連接,然后如果瀏覽器或者服務器在其頭信息加入了這行代碼
Connection:keep-alive TCP連接在發送后將仍然保持打開狀態,于是,瀏覽器可以繼續通過相同的連接發送請求。保持連接節省了為每個請求建立新連接所需的時間,還節約了網絡帶寬。
HTTP工作過程用到的概念
報文格式
HTTP1.0的報文有兩種類型:請求和響應。其報文格式分別為:
請求報文格式
請求方法 URL HTTP/版本號
請求首部字段(可選)
空行
body(只對Post請求有效) 例如:
GET http://m.baidu.com/ HTTP/1.1
Host m.baidu.com
Connection Keep-Alive
...// 其他header
key=iOS 響應報文格式
HTTP/版本號 返回碼 返回碼描述
應答首部字段(可選)
空行
body 例如:
HTTP/1.1 200 OK
Content-Type text/html;charset=UTF-8
...// 其他header
<html>... URL的結構
使用HTTP協議訪問資源是通過URL(Uniform Resource Locator)統一資源定位符來實現的。URL的格式如下:
scheme://host:port/path?query
scheme: 表示協議,如Http, Https, Ftp等;
host: 表示所訪問資源所在的主機名:如:www.baidu.com;
port: 表示端口號,默認為80;
path: 表示所訪問的資源在目標主機上的儲存路徑;
query: 表示查詢條件;
例如: http://www.baidu.com/search?words=Baidu HTTP的請求方法
GET: 獲取URL指定的資源;
POST:傳輸實體信息
PUT:上傳文件
DELETE:刪除文件
HEAD:獲取報文首部,與GET相比,不返回報文主體部分
OPTIONS:詢問支持的方法
TRACE:追蹤請求的路徑;
CONNECT:要求在與代理服務器通信時建立隧道,使用隧道進行TCP通信。主要使用SSL和TLS將數據加密后通過網絡隧道進行傳輸。 報文字段
HTTP首部字段由字段名和字段值組成,中間以":"分隔,如Content-Type: text/html.其中,同一個字段名可對應多個字段值。
HTTP的報文字段分為5種:
- 請求報文字段
- 應答報文字段
- 實體首部字段
- 通用報文字段
- 其他報文字段
請求報文字段
HTTP請求中支持的報文字段。
Accept:客戶端能夠處理的媒體類型。如text/html, 表示客戶端讓服務器返回html類型的數據,如果沒有,返回text
類型的也可以。媒體類型的格式一般為:type/subType, 表示優先請求subType類型的數據,如果沒有,返回type類型
數據也可以。
常見的媒體類型:
文本文件:text/html, text/plain, text/css, application/xml
圖片文件:iamge/jpeg, image/gif, image/png;
視頻文件:video/mpeg
應用程序使用的二進制文件:application/octet-stream, application/zip
Accept字段可設置多個字段值,這樣服務器依次進行匹配,并返回最先匹配到的媒體類型,當然,也可通過q參數來設置
媒體類型的權重,權重越高,優先級越高。q的取值為[0, 1], 可取小數點后3位,默認為1.0。例如:
Accept: text/html, application/xml; q=0.9, */*
Accept-Charset: 表示客戶端支持的字符集。例如:Accept-Charset: GB2312, ISO-8859-1
Accept-Encoding: 表示客戶端支持的內容編碼格式。如:Accept-Encoding:gzip
常用的內容編碼:
gzip: 由文件壓縮程序gzip生成的編碼格式;
compress: 由Unix文件壓縮程序compress生成的編碼格式;
deflate: 組合使用zlib和deflate壓縮算法生成的編碼格式;
identity:默認的編碼格式,不執行壓縮。
Accept-Language:表示客戶端支持的語言。如:Accept-Language: zh-cn, en
Authorization:表示客戶端的認證信息。客戶端在訪問需要認證的也是時,服務器會返回401,隨后客戶端將認證信息
加在Authorization字段中發送到服務器后,如果認證成功,則返回200. 如Linux公社下的Ftp服務器就是這種流程:
ftp://ftp1.linuxidc.com。
Host: 表示訪問資源所在的主機名,即URL中的域名部分。如:m.baidu.com
If-Match: If-Match的值與所請求資源的ETag值(實體標記,與資源相關聯。資源變化,實體標記跟著變化)一致時,
服務器才處理此請求。
If-Modified-Since: 用于確認客戶端擁有的本地資源的時效性。 如果客戶端請求的資源在If-Modified-Since指定
的時間后發生了改變,則服務器處理該請求。如:If-Modified-Since:Thu 09 Jul 2018 00:00:00, 表示如果客戶
端請求的資源在2018年1月9號0點之后發生了變化,則服務器處理改請求。通過該字段我們可解決以下問題:有一個包含大
量數據的接口,且實時性較高,我們在刷新時就可使用改字段,從而避免多余的流量消耗。
If-None-Match: If-Match的值與所請求資源的ETag值不一致時服務器才處理此請求。
If-Range: If-Range的值(ETag值或時間)與所訪問資源的ETag值或時間相一致時,服務器處理此請求,并返回
Range字段中設置的指定范圍的數據。如果不一致,則返回所有內容。If-Range其實算是If-Match的升級版,因為它
的值不匹配時,依然能夠返回數據,而If-Match不匹配時,請求不會被處理,需要數據時需再次進行請求。
If-Unmodified-Since:與If-Modified-Since相反,表示請求的資源在指定的時間之后未發生變化時,才處理請求,
否則返回412。
Max-Forwards:表示請求可經過的服務器的最大數目,請求每被轉發一次,Max-Forwards減1,當Max-Forwards為0
時,所在的服務器將不再轉發,而是直接做出應答。通過此字段可定位通信問題,比如之前支付寶光纖被挖斷,就可通過設
置Max-Forwards來定位大概的位置。
Proxy-Authorization:當客戶端接收到來自代理服務器的認證質詢時,客戶端會將認證信息添加到
Proxy-Authorization來完成認證。與Authorization類似,只不過Authorization是發生在客戶端與服務端之間。
Range:獲取部分資源,例如:Range: bytes=500-1000表示獲取指定資源的第500到1000字節之間的內容,如果服務器
能夠正確處理,則返回206作為應答,表示返回了部分數據,如果不能處理這種范圍請求,則以200作為應答,返回完整的
數據,
Referer:告知服務器請求是從哪個頁面發起的。例如在百度首頁中搜索某個關鍵字,結果頁面的請求頭部就會有這個字段,
其值為https://www.baidu.com/。通過這個字段可統計廣告的點擊情況。
User-Agent:將發起請求的瀏覽器和代理名稱等信息發送給服務端,例如:
User-Agent: Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/63.0.3239.84 Mobile Safari/537.36 應答報文字段
HTTP應答中支持的報文字段。
表示不能處理。
Age:服務端告知客戶端,源服務器(而不是緩存服務器)在多久之前創建了響應。
單位為秒。
ETag: 實體資源的標識,可用來請求指定的資源。
Location:請求的資源所在的新位置。
Proxy-Authenticate:將代理服務器需要的認證信息發送給客戶端。
Retry-After:服務端告知客戶端多久之后再重試,一般與503和3xx重定向類型的應答一起使用。
Server:告知服務端當前使用的HTTP服務器應用程序的相關信息。
WWW-Authenticate:告知客戶端適用于所訪問資源的認證方案,如Basic或Digest。401的響應中肯定帶有
WWW-Authenticate字段。 實體首部字段
Allow:通知客戶端,服務器所支持的請求方法。但服務器收到不支持的請求方法時,會以405(Method Not Allowed)
作為響應。
Content-Encoding:告知客戶端,服務器對資源的內容編碼。
Content-Language:告知客戶端,資源所使用的自然語言。
Content-Length:告知客戶端資源的長度
Content-Location:告知客戶端資源所在的位置。
Content-Type:告知客戶端資源的媒體類型,取值同請求首部字段中的Accept。
Expires:告知客戶端資源的失效日期。可用于對緩存的處理。
Last-Modified:告知客戶端資源最后一次修改的時間。 通用報文字段
即可在HTTP請求中使用,也可在HTTP應答中使用的報文字段。
Cache-Control:控制緩存行為;
Connection:管理持久連接,設置其值為Keep-Alive可實現長連接。
Date:創建HTTP報文的日期和時間。
Pragma:Http/1.1之前的歷史遺留字段,僅作為HTTP/1.0向后兼容而定義,雖然是通用字段,當通常被使用在客戶單的
請求中,如Pragma: no-cache, 表示客戶端在請求過程中不循序服務端返回緩存的數據;
Transfer-Encoding:規定了傳輸報文主題時使用的傳輸編碼,如Transfer-Encoding: chunked
Upgrade: 用于檢查HTTP協議或其他協議是否有可使用的更高版本。
Via:追蹤客戶端和服務端之間的報文的傳輸路徑,還可避免會環的發生,所以在經過代理時必須添加此字段。
Warning:Http/1.1的報文字段,從Http/1.0的AfterRetry演變而來,用來告知用戶一些與緩存相關的警告信息。 其他報文字段
這些字段不是HTTP協議中定義的,但被廣泛應用于HTTP請求中。
-
Cookie:屬于請求型報文字段,在請求時添加Cookie, 以實現HTTP的狀態記錄。
-
Set-Cookie:屬于應答型報文字段。服務器給客戶端傳遞Cookie信息時,就是通過此字段實現的。
Set-Cookie的字段屬性:
NAME=VALUE:賦予Cookie的名稱和值;
expires=DATE: Cookie的有效期;
path=PATH: 將服務器上的目錄作為Cookie的適用對象,若不指定,則默認為文檔所在的文件目錄;
domin=域名:作為Cookies適用對象的域名,若不指定,則默認為創建Cookie的服務器域名;
Secure: 僅在HTTPS安全通信是才會發送Cookie;
HttpOnly: 使Cookie不能被JS腳本訪問;
如:Set-Cookie:BDSVRBFE=Go; max-age=10; domain=m.baidu.com; path=/ HTTP應答狀態碼
| 狀態碼 | 類別 | 描述 |
|---|---|---|
| 1xx | Informational(信息性狀態碼) | 請求正在被處理 |
| 2xx | Success(成功狀態碼) | 請求處理成功 |
| 3xx | Redirection(重定向狀態碼) | 需要進行重定向 |
| 4xx | Client Error(客戶端狀態碼) | 服務器無法處理請求 |
| 5xx | Server Error(服務端狀態碼) | 服務器處理請求時出錯 |
常見應答狀態碼:
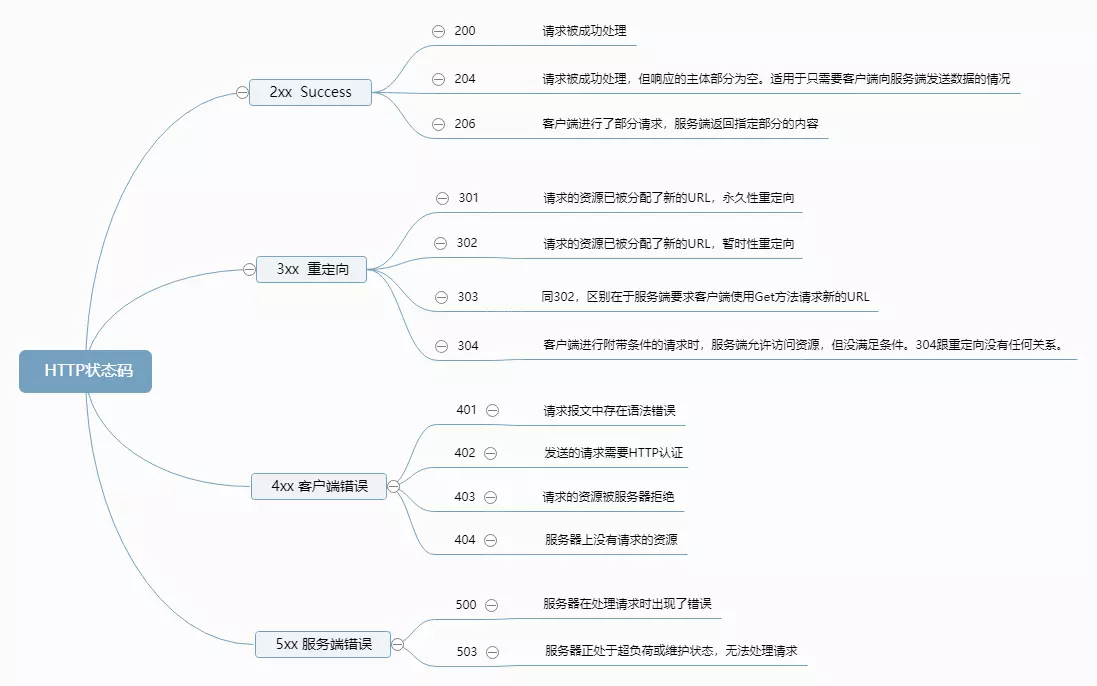
了解應答狀態碼的含義,有助于我們在開發過程中定位問題,比如出現4xx, 我們首先需要檢查的是請求是否有問題,而出現5xx時,則應讓服務端做相應的檢查工作。
HTTP缺點
- 通信使用明文,可能被竊聽
- 不驗證通信方的身份,可能遭遇偽裝
- 無法證明報文的完整性,有可能遭遇篡改
以上是HTTP的缺點,這在網絡通信中對企業安全是很致命的問題。那HTTPS能解決這些問題嗎?下面講講HTTPS。
HTTPS
HTTP+加密+認證+完整性保護 = HTTPS
HTTPS概念
引自維基百科HTTPS:超文本傳輸安全協議(英語:Hypertext Transfer Protocol Secure,縮寫:HTTPS,常稱為HTTP over TLS,HTTP over SSL或HTTP Secure)是一種通過計算機網絡進行安全通信的傳輸協議。HTTPS經由HTTP進行通信,但利用SSL/TLS來加密數據包。HTTPS開發的主要目的,是提供對網站服務器的身份認證,保護交換數據的隱私與完整性。這個協議由網景公司(Netscape)在1994年首次提出,隨后擴展到互聯網上。歷史上,HTTPS連接經常用于萬維網上的交易支付和企業信息系統中敏感信息的傳輸。在2000年代晚期和2010年代早期,HTTPS開始廣泛使用于保護所有類型網站上的網頁真實性,保護賬戶和保持用戶通信,身份和網絡瀏覽的私密性。
HTTP協議采用明文傳輸信息,存在信息竊聽、信息篡改和信息劫持的風險,而協議TLS/SSL具有身份驗證、信息加密和完整性校驗的功能,可以避免此類問題發生。
TLS/SSL全稱安全傳輸層協議Transport Layer Security, 是介于TCP和HTTP之間的一層安全協議,不影響原有的TCP協議和HTTP協議,所以使用HTTPS基本上不需要對HTTP頁面進行太多的改造。

HTTPS是在HTTP上建立SSL加密層,并對傳輸數據進行加密,是HTTP協議的安全版。HTTPS主要作用是:
- 對數據進行加密,并建立一個信息安全通道,來保證傳輸過程中的數據安全
- 對網站服務器進行真實身份認證
HTTPS和HTTP的區別

可以看到HTTPS比HTTP多了一層TLS/SSL協議,這個協議是干嘛的,有什么作用呢? 下面講解TLS/SSL工作原理。
TLS/SSL工作原理
HTTPS協議的主要功能基本都依賴于TLS/SSL協議,TLS/SSL的功能實現主要依賴于三類基本算法:散列函數 Hash、對稱加密和非對稱加密,其利用非對稱加密實現身份認證和密鑰協商,對稱加密算法采用協商的密鑰對數據加密,基于散列函數驗證信息的完整性。
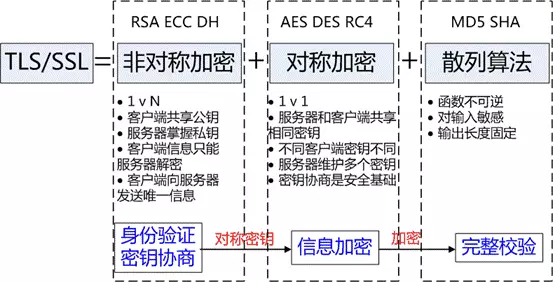
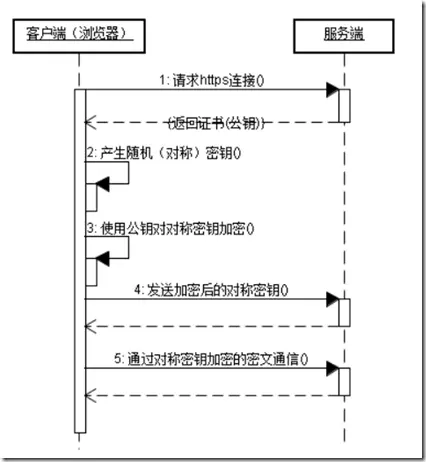
散列函數Hash
常見的有 MD5、SHA1、SHA256,該類函數特點是函數單向不可逆、對輸入非常敏感、輸出長度固定,針對數據的任何修改都會改變散列函數的結果,用于防止信息篡改并驗證數據的完整性; 在信息傳輸過程中,散列函數不能單獨實現信息防篡改,因為明文傳輸,中間人可以修改信息之后重新計算信息摘要,因此需要對傳輸的信息以及信息摘要進行加密;
對稱加密
常見的有AES-CBC、DES、3DES、AES-GCM等,相同的密鑰可以用于信息的加密和解密,掌握密鑰才能獲取信息,能夠防止信息竊聽,通信方式是1對1; 對稱加密的優勢是信息傳輸1對1,需要共享相同的密碼,密碼的安全是保證信息安全的基礎,服務器和 N 個客戶端通信,需要維持 N 個密碼記錄,且缺少修改密碼的機制;
非對稱加密
即常見的 RSA 算法,還包括 ECC、DH 等算法,算法特點是,密鑰成對出現,一般稱為公鑰(公開)和私鑰(保密),公鑰加密的信息只能私鑰解開,私鑰加密的信息只能公鑰解開。因此掌握公鑰的不同客戶端之間不能互相解密信息,只能和掌握私鑰的服務器進行加密通信,服務器可以實現1對多的通信,客戶端也可以用來驗證掌握私鑰的服務器身份。 非對稱加密的特點是信息傳輸1對多,服務器只需要維持一個私鑰就能夠和多個客戶端進行加密通信,但服務器發出的信息能夠被所有的客戶端解密,且該算法的計算復雜,加密速度慢。
結合三類算法的特點,TLS的基本工作方式是,客戶端使用非對稱加密與服務器進行通信,實現身份驗證并協商對稱加密使用的密鑰, 然后對稱加密算法采用協商密鑰對信息以及信息摘要進行加密通信,不同的節點之間采用的對稱密鑰不同,從而可以保證信息只能通信雙方獲取。
PKI體系
RSA身份驗證的隱患
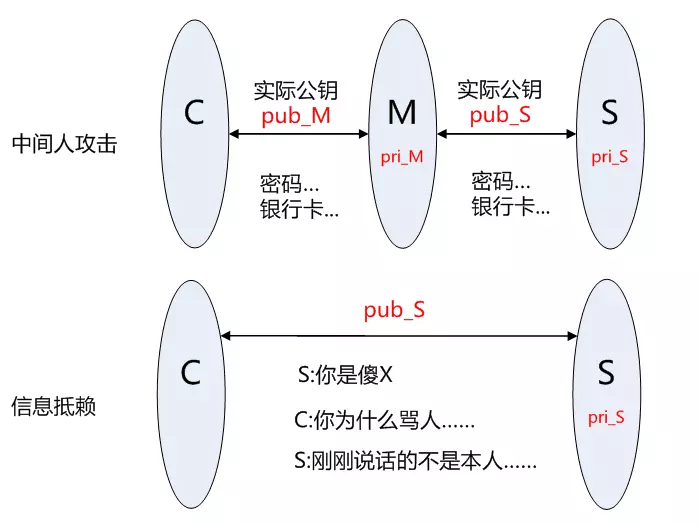
身份驗證和密鑰協商是TLS的基礎功能,要求的前提是合法的服務器掌握著對應的私鑰。但RSA算法無法確保服務器身份的合法性,因為公鑰并不包含服務器的信息,存在安全隱患:
- 客戶端C和服務器S進行通信,中間節點M截獲了二者的通信;
- 節點M自己計算產生一對公鑰pub_M和私鑰pri_M;
- C向S請求公鑰時,M把自己的公鑰pub_M發給了C;
- C使用公鑰 pub_M加密的數據能夠被M解密,因為M掌握對應的私鑰pri_M,而 C無法根據公鑰信息判斷服務器的身份,從而 C和 * M之間建立了"可信"加密連接;
- 中間節點 M和服務器S之間再建立合法的連接,因此 C和 S之間通信被M完全掌握,M可以進行信息的竊聽、篡改等操作。
- 另外,服務器也可以對自己的發出的信息進行否認,不承認相關信息是自己發出。
因此該方案下至少存在兩類問題:中間人攻擊和信息抵賴。
身份驗證CA和證書
解決上述身份驗證問題的關鍵是確保獲取的公鑰途徑是合法的,能夠驗證服務器的身份信息,為此需要引入權威的第三方機構CA(如沃通CA)。CA 負責核實公鑰的擁有者的信息,并頒發認證"證書",同時能夠為使用者提供證書驗證服務,即PKI體系(PKI基礎知識)。
基本的原理為,CA負責審核信息,然后對關鍵信息利用私鑰進行"簽名",公開對應的公鑰,客戶端可以利用公鑰驗證簽名。CA也可以吊銷已經簽發的證書,基本的方式包括兩類 CRL 文件和 OCSP。CA使用具體的流程如下:
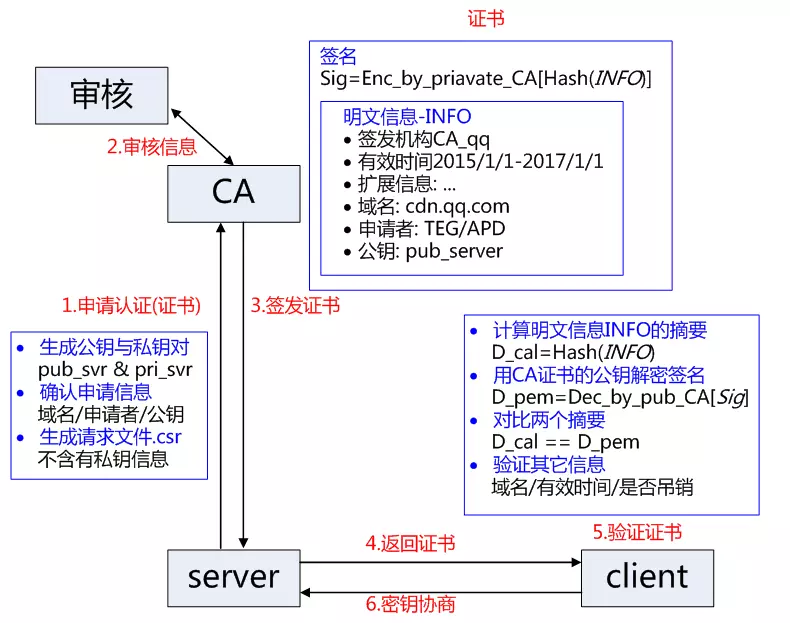
a.服務方S向第三方機構CA提交公鑰、組織信息、個人信息(域名)等信息并申請認證;
b.CA通過線上、線下等多種手段驗證申請者提供信息的真實性,如組織是否存在、企業是否合法,是否擁有域名的所有權等;
c.如信息審核通過,CA會向申請者簽發認證文件-證書。 證書包含以下信息:申請者公鑰、申請者的組織信息和個人信息、簽發機構 CA的信息、有效時間、證書序列號等信息的明文,同時包含一個簽名; 簽名的產生算法:首先,使用散列函數計算公開的明文信息的信息摘要,然后,采用 CA的私鑰對信息摘要進行加密,密文即簽名;
d.客戶端 C 向服務器 S 發出請求時,S 返回證書文件;
e.客戶端 C讀取證書中的相關的明文信息,采用相同的散列函數計算得到信息摘要,然后,利用對應 CA的公鑰解密簽名數據,對比證書的信息摘要,如果一致,則可以確認證書的合法性,即公鑰合法;
f.客戶端然后驗證證書相關的域名信息、有效時間等信息;
g.客戶端會內置信任CA的證書信息(包含公鑰),如果CA不被信任,則找不到對應 CA的證書,證書也會被判定非法。
在這個過程注意幾點:
a.申請證書不需要提供私鑰,確保私鑰永遠只能服務器掌握;
b.證書的合法性仍然依賴于非對稱加密算法,證書主要是增加了服務器信息以及簽名;
c.內置 CA 對應的證書稱為根證書,頒發者和使用者相同,自己為自己簽名,即自簽名證書(為什么說"部署自簽SSL證書非常不安全")
d.證書=公鑰+申請者與頒發者信息+簽名;
證書鏈
如 CA根證書和服務器證書中間增加一級證書機構,即中間證書,證書的產生和驗證原理不變,只是增加一層驗證,只要最后能夠被任何信任的CA根證書驗證合法即可。
a.服務器證書 server.pem 的簽發者為中間證書機構 inter,inter 根據證書 inter.pem 驗證 server.pem 確實為自己簽發的有效證書;
b.中間證書 inter.pem 的簽發 CA 為 root,root 根據證書 root.pem 驗證 inter.pem 為自己簽發的合法證書;
c.客戶端內置信任 CA 的 root.pem 證書,因此服務器證書 server.pem 的被信任。
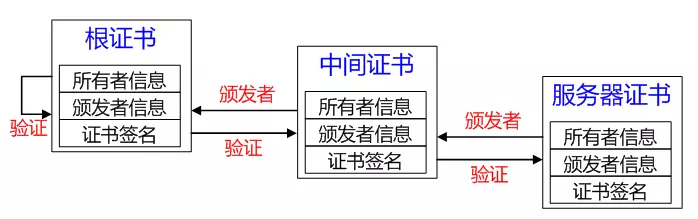
服務器證書、中間證書與根證書在一起組合成一條合法的證書鏈,證書鏈的驗證是自下而上的信任傳遞的過程。 二級證書結構存在的優勢:
a.減少根證書結構的管理工作量,可以更高效的進行證書的審核與簽發;
b.根證書一般內置在客戶端中,私鑰一般離線存儲,一旦私鑰泄露,則吊銷過程非常困難,無法及時補救;
c.中間證書結構的私鑰泄露,則可以快速在線吊銷,并重新為用戶簽發新的證書;
d.證書鏈四級以內一般不會對 HTTPS 的性能造成明顯影響。

證書鏈有以下特點:
a.同一本服務器證書可能存在多條合法的證書鏈。 因為證書的生成和驗證基礎是公鑰和私鑰對,如果采用相同的公鑰和私鑰生成不同的中間證書,針對被簽發者而言,該簽發機構都是合法的 CA,不同的是中間證書的簽發機構不同;
b.不同證書鏈的層級不一定相同,可能二級、三級或四級證書鏈。 中間證書的簽發機構可能是根證書機構也可能是另一個中間證書機構,所以證書鏈層級不一定相同。
證書吊銷
CA 機構能夠簽發證書,同樣也存在機制宣布以往簽發的證書無效。證書使用者不合法,CA 需要廢棄該證書;或者私鑰丟失,使用者申請讓證書無效。主要存在兩類機制:CRL 與 OCSP。
CRL
Certificate Revocation List, 證書吊銷列表(什么是證書吊銷列表(CRL)?吊銷列表起什么作用),一個單獨的文件。該文件包含了 CA 已經吊銷的證書序列號(唯一)與吊銷日期,同時該文件包含生效日期并通知下次更新該文件的時間,當然該文件必然包含 CA 私鑰的簽名以驗證文件的合法性。 證書中一般會包含一個 URL 地址 CRL Distribution Point,通知使用者去哪里下載對應的 CRL 以校驗證書是否吊銷。該吊銷方式的優點是不需要頻繁更新,但是不能及時吊銷證書,因為 CRL 更新時間一般是幾天,這期間可能已經造成了極大損失。
OCSP
Online Certificate Status Protocol, 證書狀態在線查詢協議,一個實時查詢證書是否吊銷的方式。請求者發送證書的信息并請求查詢,服務器返回正常、吊銷或未知中的任何一個狀態。證書中一般也會包含一個 OCSP 的 URL 地址,要求查詢服務器具有良好的性能。部分 CA 或大部分的自簽 CA (根證書)都是未提供 CRL 或 OCSP 地址的,對于吊銷證書會是一件非常麻煩的事情。
HTTPS性能與優化
HTTPS性能損耗
前文討論了HTTPS原理與優勢:身份驗證、信息加密與完整性校驗等,且未對TCP和HTTP協議做任何修改。但通過增加新協議以實現更安全的通信必然需要付出代價,HTTPS協議的性能損耗主要體現如下:
- 增加延時
分析前面的握手過程,一次完整的握手至少需要兩端依次來回兩次通信,至少增加延時2* RTT,利用會話緩存從而復用連接,延時也至少1* RTT*
- 消耗較多的CPU資源
除數據傳輸之外,HTTPS通信主要包括對對稱加解密、非對稱加解密(服務器主要采用私鑰解密數據);壓測 TS8 機型的單核 CPU:對稱加密算法AES-CBC-256 吞吐量 600Mbps,非對稱 RSA 私鑰解密200次/s。不考慮其它軟件層面的開銷,10G 網卡為對稱加密需要消耗 CPU 約17核,24核CPU最多接入 HTTPS 連接 4800; 靜態節點當前10G 網卡的 TS8 機型的 HTTP 單機接入能力約為10w/s,如果將所有的HTTP連接變為HTTPS連接,則明顯RSA的解密最先成為瓶頸。因此,RSA的解密能力是當前困擾HTTPS接入的主要難題。
HTTPS接入優化
CDN接入
HTTPS 增加的延時主要是傳輸延時 RTT,RTT 的特點是節點越近延時越小,CDN 天然離用戶最近,因此選擇使用 CDN 作為 HTTPS 接入的入口,將能夠極大減少接入延時。CDN 節點通過和業務服務器維持長連接、會話復用和鏈路質量優化等可控方法,極大減少 HTTPS 帶來的延時。
會話緩存
雖然前文提到 HTTPS 即使采用會話緩存也要至少1*RTT的延時,但是至少延時已經減少為原來的一半,明顯的延時優化;同時,基于會話緩存建立的 HTTPS 連接不需要服務器使用RSA私鑰解密獲取 Pre-master 信息,可以省去CPU 的消耗。如果業務訪問連接集中,緩存命中率高,則HTTPS的接入能力講明顯提升。當前TRP平臺的緩存命中率高峰時期大于30%,10k/s的接入資源實際可以承載13k/的接入,收效非常可觀。
硬件加速
為接入服務器安裝專用的SSL硬件加速卡,作用類似 GPU,釋放 CPU,能夠具有更高的 HTTPS 接入能力且不影響業務程序的。測試某硬件加速卡單卡可以提供35k的解密能力,相當于175核 CPU,至少相當于7臺24核的服務器,考慮到接入服務器其它程序的開銷,一張硬件卡可以實現接近10臺服務器的接入能力。
遠程解密
本地接入消耗過多的 CPU 資源,浪費了網卡和硬盤等資源,考慮將最消耗 CPU 資源的RSA解密計算任務轉移到其它服務器,如此則可以充分發揮服務器的接入能力,充分利用帶寬與網卡資源。遠程解密服務器可以選擇 CPU 負載較低的機器充當,實現機器資源復用,也可以是專門優化的高計算性能的服務器。當前也是 CDN 用于大規模HTTPS接入的解決方案之一。
SPDY/HTTP2
前面的方法分別從減少傳輸延時和單機負載的方法提高 HTTPS 接入性能,但是方法都基于不改變 HTTP 協議的基礎上提出的優化方法,SPDY/HTTP2 利用 TLS/SSL 帶來的優勢,通過修改協議的方法來提升 HTTPS 的性能,提高下載速度等。
轉載請注明出處 AE博客|墨淵 ? HTTP和HTTPS詳解
發表評論